Como bloquear o ChatGPT de usar o conteúdo do seu site?

O ChatGPT acessa conteúdos de qualquer tipo de site, seja ele um blog, site de notícias ou e-commerce, para aprender a partir disso. Veja abaixo uma forma de impedir que o conteúdo do seu site se torne fonte de treinamento da Inteligência Artificial (AI).
Graças a explosão das tecnologias de modelos de grande linguagem (LLMs) nos últimos meses em todo mundo, capitaneado pelo famoso ChatGPT, há também a preocupação por muitos com a falta de uma maneira prática de optar por não ter o conteúdo do próprio site usado para treinar esses modelos.
Neste artigo irei apresentar uma maneira de se buscar esse objetivo. Mas atenção, esteja ciente de que não há garantias de resultados 100% eficazes através desse método. Continue a ler para entender a razão disso e descobrir como o método funciona.
Como as AIs aprendem a partir do seu conteúdo?
Os modelos de grande linguagem (LLMs) são treinados sobre dados que tem múltiplas origens. Muitos desses bancos de dados são Open Source (código aberto) e são livremente utilizados para treinar AIs.
Alguns exemplos de tipos de fontes utilizados:
- Wikipedia
- Registros governamentais
- Livros
- Emails
- Websites rastreados
Existem atualmente portais e websites oferecendo bancos de dados que disponibilizam grandes quantidades de informação. Um desses portais é hospedado pela Amazon, ofertando milhares de dados no Registro de Dados Abertos da AWS. Só a Wikipedia aponta ao menos 28 portais para download de milhares de conjuntos de dados, incluindo o Google Dataset.
Sobre conjuntos de dados utilizados para treinar o ChatGPT
O ChatGPT é baseado no GPT-3.5, tecnologia também conhecida como InstructGPT. Os conjuntos de dados utilizados para treinar o GPT-3.5 são os mesmos utilizados no GPT-3. A maior diferença entre os dois é que o GPT-3.5 utiliza a técnica conhecida como Aprendizagem de Reforço com Feedback Humano (RLHF).
Caso queira entender mais sobre o ChatGPT sugiro que leia este outro artigo que escrevi a respeito desse tema. De acordo com o artigo científico “Language Models are Few-Shot Learners”, os cinco bancos de dados utilizados para treinar o GPT-3 e o GPT-3.5 estão descritos abaixo:
- Rastreamento comum filtrado (Common Crawl);
- WebText2;
- Books1;
- Books2;
- Wikipedia;

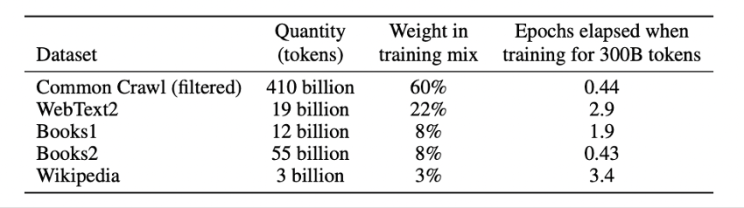
Desses cinco conjuntos de dados, dois desses são baseados no rastreio da internet, o Common Crawl e o WebText2.
Sobre o conjunto de dados WebText2
O WebText2 é um conjunto de dados privado da OpenAI (empresa dona do ChatGPT), criado a partir links publicados no Reddit que tiveram pelo menos três avaliações positivas. A premissa da lógica que utilizaram é simples, links a partir de três votos positivos tendem a ser confiáveis e fornecem conteúdo de boa qualidade.
Apesar do WebText2 não estar disponível publicamente, existe uma versão de código aberto chamada OpenWebText2. Esse é um conjunto de dados públicos que utiliza dos mesmos padrões de rastreio, que se presume oferecer um conjunto de dados de URLS similar, se não for igual, ao do WebText2 da OpenAI.
Até onde pesquisei, não foi possível identificar user-agent desses para bloqueio nos rastreadores, contudo, pode-se afirmar com bom grau de certeza de que websites vinculados ao Reddit com ao menos três avaliações positivas provavelmente estarão inclusos no conjunto de dados WebText2 da OpenAI de código fechado, assim como na versão de código aberto.
Caso seja de interesse de alguém, existe uma versão limpa do OpenWebText2 que pode ser baixada aqui, assim como a versão bruta, disponível aqui para ser analisada.
Parte 1: Sobre o Common Crawl (Rastreamento comum)
Um dos conjuntos de dados mais comumente utilizados que é constituído de conteúdos da internet é o Common Crawl, criado por uma organização sem fins lucrativos de mesmo nome.
Os dados do Common Crawl têm origem no bot “CCBot”, que rastreia toda Internet. Os dados são baixados por organizações que desejam utilizá-los, limpos de sites com spam e etc.
O CCBot obedece ao protocolo robots.txt, muito utilizado por profissionais de SEO. Assim sendo, é possível solicitar o bloqueio do Common Crawl através do robots.txt, evitando conteúdos de seu site, seja ele blog, site de notícias, e-commerce ou outro, faça parte de outro conjunto de dados.
Caso seu website já tenha sido rastreado, é provável que ele já esteja presente em múltiplos conjuntos de dados. Todavia, ao bloquear o Common Crawl é possível impedir que o conteúdo de seu website seja incluído em novos conjuntos de dados que tenham origem nos dados mais recentes do Common Crawl. E é exatamente por essa razão que o processo a ser apresentado a seguir não tem garantia de plena eficácia, ok?
A string do CCBot User-Agent é:
CCBot/2.0(Atenção: não execute as instruções a seguir sem antes ler as considerações).
Dessa forma, adicione as instruções a seguir no arquivo robots.txt do seu website para bloquear o CCBot do Common Crawl:
User-agent: CCBot
Disallow: /Lembrando que o CCBot também segue as diretrizes da meta tag nofollow. Para isso, utilize em seu robots meta tag:
<meta name="CCBot" content="nofollow">Considerações antes que você decida prosseguir:
Muitos conjuntos de dados, incluindo o Common Crawl, podem ser utilizados por empresas que filtram e categorizam URLs objetivando a criação de listas de websites para publicidade segmentada.
O conjunto de dados é útil para, por exemplo, AdTechs e para uso de publicidade contextual. Para citar um caso, a Alpha Quantum é uma empresa que oferece um conjunto de dados de URLs categorizados usando o Taxonomia do Interactive Advertising Bureau. Neste sentido, a exclusão de conjuntos de dados como esse poderia causar ao website uma perda potencial com anunciantes.
Os mecanismos de busca (tais como o Google, Bing e outros) permite que websites optem por não serem rastreados, assim também faz o Common Crawl. Contudo, atualmente não existe forma simples de remover o conteúdo de um website de conjuntos de dados já existentes.
Atualmente, há discussões a respeito do uso de dados de sites sem permissão por tecnologias de IA como o ChatGPT, mas se os editores de conteúdo terão voz para decidir como seus conteúdos são utilizados é algo que ainda não sabemos como ou se irá acontecer.
Para construir esse artigo, além das fontes previamente citadas, realizei a tradução do conteúdo publicado aqui que pode ser lido na íntegra para quem tiver interesse (em inglês).
(Atualização) Parte 2: Bloqueio através do User-Agent: ChatGPT
User-agent é um termo que se refere à identificação do agente de usuário que é enviado pelo navegador ou robô ao acessar um site.
De acordo com o próprio ChatGPT, se você deseja bloquear o ChatGPT de usar o conteúdo do seu site, a melhor opção é adicionar um arquivo robots.txt ao seu site. O arquivo robots.txt é um arquivo de texto que informa aos mecanismos de pesquisa e outros agentes de rastreamento quais páginas do seu site podem ou não ser rastreadas.
Para bloquear o ChatGPT de usar o conteúdo do seu site, você pode adicionar as seguintes linhas ao seu arquivo robots.txt:
User-agent: chatgpt
Disallow: /Essas linhas instruirão o ChatGPT a não rastrear nenhuma página do seu site.
O “User-agent: chatgpt” refere-se ao agente de usuário utilizado pelo ChatGPT, que é um modelo de linguagem de inteligência artificial treinado pela OpenAI para realizar tarefas de processamento de linguagem natural, como responder a perguntas e gerar textos. Quando o ChatGPT acessa um site, ele envia essa identificação para o servidor, permitindo que o site possa identificá-lo e tomar decisões específicas em relação a ele, como bloqueá-lo ou permitir o acesso apenas a determinadas áreas do site.
Lembre-se de que, embora o ChatGPT respeite o arquivo robots.txt, outros agentes de rastreamento podem não fazê-lo. Além disso, essa medida não garante que o conteúdo do seu site não seja acessado ou usado por outras formas de acesso à informação na Internet.
Bloqueio através de meta tag: ChatGPT
De maneira análogo ao que coloquei anteriormente, em tese também é possível realizar esse bloqueio por meio de metatags no cabeçalho da página. Aqui está um exemplo de como fazer isso:
- Crie uma metatag no cabeçalho da página com o nome “robots” e o valor “noindex, nofollow”. Isso instruirá os robôs de busca a não indexar a página nem seguir os links nela contidos.
<head>
<meta name="chatgpt" content="noindex, nofollow">
</head>- Adicione a metatag em todas as páginas do seu site que você deseja bloquear.
Considerações Finais
Vale lembrar que, caso você não seja um especialista no assunto, peça apoio de alguém que seja antes de prosseguir em qualquer uma dessas alternativas. Assim você pode evitar qualquer tipo de problema de indexação em outros bots para além do ChatGPT.
Além disso, na hipótese de nenhum dos processos expostos acima derem certo, há ainda outros meios de tentar realizar esse bloqueio, como por exemplo, através do cabeçalho HTTP X-Robots-Tag ou ainda por meio do bloqueio por senha via autenticação básica HTTP. Essa última é uma forma de proteger seu site com uma senha para impedir que usuários não autorizados acessem seu conteúdo, portanto, deve funcionar também para o ChatGPT. Caso queira que inclua isso também neste conteúdo, me mande uma mensagem. Um abraço e até uma próxima!